An Interview with Cadence
By: Arif Khan, Joe Chen, and Gautam Singampalli
The UALink Consortium is driving the development of UALink technology – an open scale-up interconnect for next generation AI workloads.
We recently met with UALink Consortium member Cadence to discuss the benefits of an open ecosystem and use cases for UALink technology. Continue reading our blog for highlights from our conversation.
Q: What is the importance of an open ecosystem?
An open ecosystem is crucial because it fosters innovation, collaboration, and interoperability. By allowing different components and systems to work together seamlessly, it reduces complexity and accelerates development. In semiconductor design, cost and complexity are closely linked. As process nodes advance, design and verification costs rise, and design cycles lengthen. Open standards and protocols enable various IP subsystems, from basic GPIOs to advanced high-speed interfaces, to integrate efficiently.
Organizations like UALink, IEEE, UEC, JEDEC, PCI-SIG, CXL, and UCIe play a vital role in defining these standards. They promote a collaborative environment that benefits the entire industry by ensuring interface IP interoperability. This openness is essential for advancing technology and meeting the growing demands of applications like AI and high-speed computing.
GPU, accelerator, and xPU architectures have evolved rapidly to keep up with AI use cases and application evolution. However, proprietary interfaces for GPU-to-GPU communication can limit performance. Scaling up accelerators and their local memory to a set of connected accelerators with robust, low-latency memory access is crucial. UALink offers a standards-based solution for the industry at large instead of a fragmented set of walled gardens defined by proprietary interfaces.
In summary, an open ecosystem is vital for fostering innovation, reducing complexity, and accelerating development not just in AI computing, but across the wider semiconductor design landscape.
References:
Celebrating World Intellectual Property Day
UALink™ Shakes up the Scale-up AI Compute Landscape
Q: Why did your company join the UALink Consortium?
Cadence, a leader in AI and a pivotal IP provider, has joined the UALink Consortium with a clear focus on advancing AI innovation. Renowned for its expertise in developing open interconnect standards, Cadence ensures seamless, high-performance communication across AI accelerators. This enables users to build scalable and efficient AI ecosystems with ease.
Through its cutting-edge IP offerings and extensive industry knowledge, Cadence is actively driving the development of these standards while underscoring its commitment to fostering innovation and addressing the evolving demands of next-generation AI technologies. Cadence is not merely participating but is at the forefront leading this transformative journey.
Q: How does UALink technology enhance AI workloads?
UALink is designed to facilitate direct load, store, and atomic operations between AI accelerators (e.g., GPUs), prioritizing low-latency and high-bandwidth communication for hundreds of accelerators within a pod. It is achieved through simple load and store semantics with software-based coherency, streamlining operations across interconnected systems. Furthermore, by leveraging advanced features like packet compression and Split Request/Response messages, UALink significantly enhances bandwidth utilization, boosting efficiency from 88% to an impressive 95%. Additional advanced techniques, such as 1-way and 2-way FEC interleaving and the efficient packing of UPLI transactions into TL-Flits, further reduce controller latency, ensuring optimal performance.
Q: What are some use cases for UALink technology?
Efficient scaling of AI accelerators is essential for achieving optimal performance and throughput in demanding workloads. These use cases highlight UALink’s role in enhancing performance, scalability, and interoperability in advanced computing environments.
- Efficient Scaling of AI Accelerators: UALink is essential for achieving optimal performance and throughput in demanding AI workloads. It facilitates low-latency, high-bandwidth communication between accelerators, making it the de-facto standard for AI accelerator interconnects.
- Unified Compute Space: UALink helps assemble multiple compute nodes to act as a single large processor or accelerator with unified addresses. This is vital for training AI models that require extensive computational resources.
- High-Intensity Workloads: UALink is suitable for high-intensity workloads in AI and HPC data centers, where compute nodes need to reach beyond the chip or package for additional resources.
- Custom Accelerator Designs: UALink supports custom accelerator designs, addressing unique system solutions in the generative AI space. It abstracts away the divisions between accelerators, enabling seamless communication and resource sharing.
- Intra-Pod and Pod Expansion: UALink supports intra-pod xPU-to-xPU traffic over its scale-up network, managed by a UALink switch. For scale-out, Ultra Ethernet handles OS operations, memory management, and information sharing across hosts and remote accelerators.
The scalability of AI systems becomes even more apparent when examining their interconnectivity. Figure 6 from UALink™ Shakes up the Scale-up AI Compute Landscape
Article illustrates a system diagram that highlights the seamless interaction between various protocols within a UALink-capable system node. Intra-pod xPU-to-xPU traffic operates over the UALink scale-up network, supported by a UALink switch.
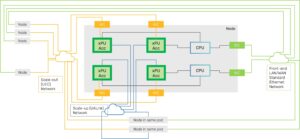 UALink Node in a system and its interaction with other standards
UALink Node in a system and its interaction with other standards
References:
UALink™ Shakes up the Scale-up AI Compute Landscape
New Data Center Protocols Tackle AI